



Key Features
- 15 Mastery Classes
Begin your adventure as a base class which can then specialize into one of three Mastery Classes. When specializing into a certain Mastery you will be able to access new skills and specialize your playstyle! - Customize each skill
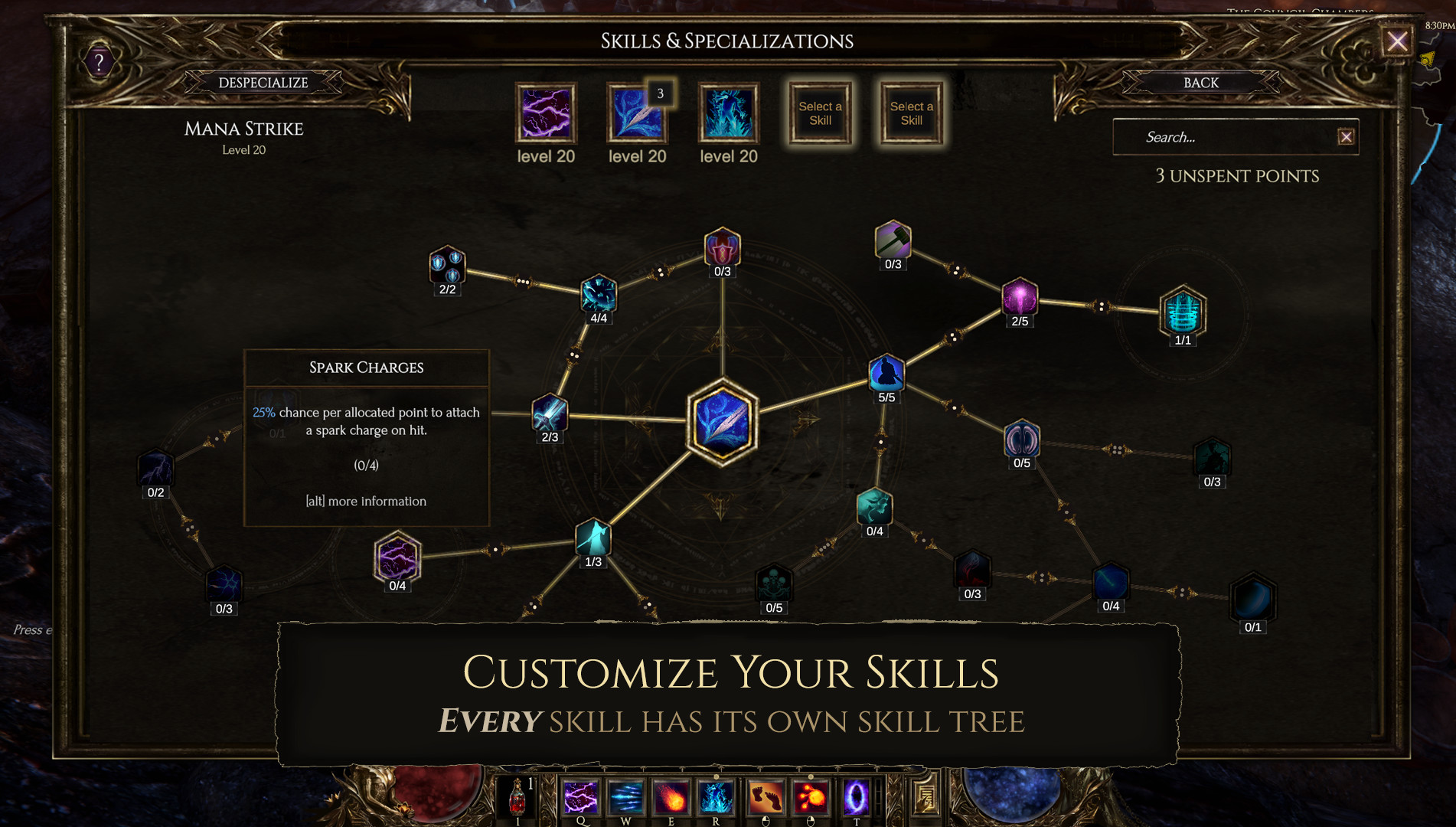
Every active skill has its own augment tree that can completely change how the skill functions. Transform your skeletons into archers, your lightning blast into chain lightning, or make your serpent strike summon snakes to fight alongside you! - Lose yourself in the item hunt
Fill your arsenal with magic items you craft to perfection, change the rules of your build with powerful unique and set items, and always have that next upgrade just on the horizon with Last Epoch's randomized loot system. - Explore a vast world throughout time
The world of Eterra is home to many factions and secrets. Travel to different points in time to change the world's fate, and fight to set it onto a new path. - Endless replayability
With a wealth of classes and skills to customize, deep game systems, randomized loot, and continuing development, Last Epoch is a game that will keep you coming back. - Easy to learn, hard to master
We're committed to making our gameplay approachable through breaking up the required learning and being transparent. At the same time, overcoming some of the most challenging content will require deep knowledge and pushing your build to its limits.
🕹️ Partial Controller Support
Hello Travelers!
Todays blog is a little different from our usual fare. As most of you know, Last Epoch launched on February 21, and the reception has been amazing. In the first week after launch, over 1.4 million of you logged in to play Last Epoch. At our peak, we had just under 265,000 players all roaming Eterra simultaneously. Thats good enough for the 39th highest all-time concurrent player count recorded on Steam, and were humbled by your support and enthusiasm for the game.
Theres plenty of cause for celebration, but lets not ignore the obvious: Last Epochs launch was pretty rough for the majority of you who play online. Your patience and positivity have been amazing, but it was obviously not the launch experience that you or we had hoped for.
Now that the initial launch woes are behind us, its time to reflect on the experience. What happened? We put a strong emphasis on testing our servers and infrastructure ahead of time, so what did we get wrong? Last Epochs backend team is here to give you a bit of a recap of what went on during the launch.
How Our Game Works
Lets begin with a quick explanation of how our game works when played online. When you boot up Last Epoch and enter the game, what you see as a player is relatively straightforward; first you log in, then you select your character, and then you join a game server. Behind the scenes, though, what youve just done is communicate with and move through half a dozen online services. These services log you in, provide you with game data, and give you a server to connect to so you can play the game. You connect to this game server, but then the server itself goes out and talks to even more services to authenticate you, load your character data, and check things like your party membership.
These supporting services are the backend of our game, and without them our game doesnt work. Some services are more important than others, but as a general rule, most services are required for the game to function. The good news is these services are all pretty resilient. Behind the scenes, each service is not one program but many copies of the same program. If one of the copies breaks down, the other copies keep working. Crucially, if a service is overloaded, we can fix that by just deploying more copies of the program. If our services are designed properly, we can handle any number of players; all we need to do is throw more copies at the problem.
(This design applies to our game servers, too; Last Epoch has never once run out of game servers for players because theyre all interchangeable, and we can create as many new ones as we need. The closest we ever come to running out of servers is when we get a spike in players and need to wait a short amount of time for extra ones to boot up).
Preparing For Launch
The designing our services properly bit is the hard part. For some of our services, its very challenging to design them in a way that actually lets us scale just by throwing more copies at the problem. If you were around for the launch of patch 0.9.0, our first multiplayer release, you saw our game go down as soon as we crossed 40,000 players. Why? The service that matches players to servers had a design flaw where it started slowing down when there were many servers available. Once about 40,000 players joined servers, the performance of the matcher got so bad that it didnt matter how many copies we threw at the problem - every copy would crash under the strain.
The backend team spent much of the time between 0.9.0 and 1.0.0 hunting down and fixing these sorts of design flaws. Some flaws could be fixed easily, others required entirely new services to handle our players data in a way that could actually scale. We were given a blank check to do whatever was needed to support our launch, so the only obstacle was time.
By the week before launch, we seemed to be in a reasonably comfortable spot. Everything was built, and wed performed multiple rounds of load testing on our entire backend to ensure it could handle the volume of requests we expected at launch. The results were promising, and we hadnt pulled any punches on the testing either. We were as ready as we were ever going to be for launch.
The Morning Of Launch
For something like a game launch, readiness is mostly about having a plan. You can have confidence that youve tested and prepared, you can have confidence that you know how your services work, but you cant have confidence that nothing will go wrong. Instead, you plan for what to do if something unanticipated happens.
On the morning of launch day, we went to scale up our server matching service to the numbers we used in our tests, and to our great surprise, it refused to spin up more than half the copies we asked for. Server matching is a critical service, and in our testing, it needed a high number of copies to handle all the players we expected, so getting stuck at half capacity was a serious problem.
This wasnt even the only pre-launch hiccup. In a case of unfortunate timing, our service host had an incident the night before - still ongoing at launch time - that affected us in a way that prevented us from deploying changes to any of our backend services using the tools we had relied on for months. Our ability to fix our services was killed at the same time one of our services needed fixing.
We had workarounds for these problems, but they were not quick fixes. We were going to need to break apart our deployment tools and move our services around manually, but this was not something we could sneak in before the doors opened to all our players. Minutes before launch, we estimated that we could handle maybe 120,000 - 150,000 players before things started to fail, and we crossed our fingers that wed be able to resolve our issues before the player count crept too high.
Well, you know how that went.
The Next 5 Days
What unfolded over the next five days was a blur of emergency fixes and risk management. As it so happened, our first two pre-launch problems were only the tip of the iceberg.
In software, you sometimes run into a problem called cascading failure. When different parts of a software system rely on each other, an error in one part can cause errors in all the other parts as well. This can make it look like the entire system is failing even though only one part actually is. Finding the root cause of the failure is very difficult when everything is failing all at once.
The server matcher problem had caused a cascading failure in our systems. When players fail to connect to a server, they usually just try again, meaning our struggling server matcher had to deal with 2-5x the number of requests it would normally need to deal with. In many cases, players would get through the first half of server matching but would fail the second half, meaning servers would bring themselves online and then shut down again because a player never connected. Servers booting up and shutting down put pressure on our other services, and so some of those also started to fail.
When we fixed the server matcher, some other services continued to fail because they had trouble recovering from the chaos. Our deployment tools still required attention, so fixing these other services was a slow and manual process. To clear up the backlog, we needed to scale some of our services way past what would have been needed had the game been working smoothly. This brought with it new challenges since cloud services have some built-in soft caps that we would never have hit under normal circumstances, and working around those caps took time and, in some cases, code changes. We identified and cleared away many of these caps before launch, but we hit new ones as we scrambled to rearrange our backend.
You may be wondering, if the problem was recovering from too many players, why did we not simply have some downtime, or at least turn on player queues, to alleviate the pressure? The answer is that we did, but the problems ran deeper than the server matcher. At various points during the launch, we brought down our services, and many of you found yourselves in long queues as we struggled to keep up. Inevitably, once we started letting you all back in, we would run into problems again, and we could not clearly see what those problems were until we scaled everything up so high that the services stayed online and operational even though they were strained from other failures in other areas.
Sprinkled in with our deployment woes, we had a couple of genuine code problems in our services. One of them - one of the few examples where we straight up overestimated our ability to scale - was a bottleneck in how quickly we could process requests for a single town in a single region of the world. In Last Epoch, once you reach the End of Time town, you will always load into that town when you enter the game from character select. We knew ahead of time that this bottleneck existed, but we underestimated what would happen when we suddenly fixed a broken game and hundreds of thousands of players all tried to access the same town at the same time, in the same part of the world. We thought that the server matcher would be a little slow at first, and then it would start to fix itself as more and more people got into the game. What happened instead was that it took so long to get into the game that almost no one actually succeeded, so they quit and tried again, over and over, and the problem never tapered off. This was not the kind of problem we could fix just by adding more copies of the service, so it took some emergency problem solving.
Each time we found a problem and fixed it, we immediately saw improvement, but this allowed even more players to enter the game and play, which would uncover the next problem, and so on.
The Final Fix
By Sunday, we had managed to fix, deploy, and scale our services to the point that most of our backend was handling over 200,000 players just fine, even through flurries of retries and errors. Yet amidst all the chaos, there was still some strange behavior happening on the game servers that was causing problems. During our periods of stability, when the game was up, players were able to connect to game servers, but their connections would often time-out once they got there.
Every time a player joins a game server, the game server checks to see if the player is in a party. This is a simple operation, and in all of our testing, we saw that this check completed very quickly, even under heavy load. Yet our logs were telling us that checks for a players party were taking up to a minute, sometimes even longer.
Over the first four days, we made a number of changes to the party service to alleviate pressure. Each fix helped for a while, but inevitably, it always slowed down again until players could no longer join servers. On day five, with all the other backend problems solved, we were able to get a more precise look at the party errors, and the culprit was a single, innocent-looking line of code. A single line of code that was supposed to be the most efficient request in our entire party service but instead ended up consuming all of the services resources under heavy load, slowing the entire service to a crawl.
It took about an hour on Sunday afternoon to rearrange the party data so we could check over 200,000 players party memberships without bringing down the service. We deployed the fix, the game came back up, and its been online ever since.
Lessons Learned
This blog post is 2,000 words long, and there is still a whole lot more we could say. Internally, we have been cataloging and planning for ways we can improve, and we want to ensure that our processes moving forward include the lessons we have learned from the launch.
First, we learned the hard way that our internal tooling for deploying our services was not robust enough on launch day. Our tools were too brittle (breaking when certain services went down) and too inflexible (too many manual adjustments needed in an emergency). When the system came under strain, we couldnt deploy our fixes quickly, and we usually had to cause additional downtime to do it. Had our deploy tooling been stronger, we could have gotten to a stable state much more quickly. Our top priority on the team right now is improving our tooling so we can effectively respond to situations like these.
Second, our services themselves could be more flexible. We had to make many changes over the course of the launch that should have been simple configuration changes but instead required a full redeploy, which turned simple fixes into long, risky operations. This weakness was identified ahead of time and has now become a top priority to improve.
Third, we need to do a better job of anticipating how player behavior affects our backend. Our testing was designed to simulate how and when our services would break, but we needed to spend more time considering how the conditions would continue to change once things started failing. Now that weve seen what happens during a fraught launch - how players put pressure on services differently than when everything is working - well be able to incorporate that data into future tests.
(As an aside, our testing effort, in general, was a huge success. Despite how it may look from our launch struggles, our testing identified many other critical issues leading all the way up to the week before launch, and without those efforts, we might still be trying to fix the game to this day. Even though were post-launch, we plan to continue incorporating load testing into our regular development cadence going forward.)
Thank You
With the launch behind us, were all very thankful to you players for showing so much passion for the game, despite the rocky start.
EHG started from a group of gamers hoping to make the ARPG they wanted to play, and now EHG is a group of gamers hoping to make the game YOU want to play. Your passion, enthusiasm and, when deserved, criticism have continued to encourage our teams to deliver that game and push the definition of what an ARPG can be, should be, and will be. Our team could not have made Last Epoch what it is today without you, and we will endeavor to keep making the game you all deserve.
Here's to a bright future, Travelers.
Minimum Setup
- OS: Ubuntu 16.04
- Processor: Intel Core i5 2500 or AMD FX-4350Memory: 6 GB RAM
- Memory: 6 GB RAM
- Graphics: nVidia GTX 660ti or AMD R9 270 with 2+ GB of VRAMNetwork: Broadband Internet connection
- Storage: 20 GB available space
Recommended Setup
- OS: Ubuntu 18.04
- Processor: Intel Core i5 6500 or AMD Ryzen 3 1200Memory: 8 GB RAM
- Graphics: nVidia GTX 1060 or AMD RX 480 with 4+ GB of VRAMNetwork: Broadband Internet connection
- Storage: 20 GB available space

[ 6370 ]
[ 5870 ]
[ 1265 ]
[ 1943 ]
[ 986 ]

Time left:
356100 days, 0 hours, 25 minutes

Time left:
356100 days, 0 hours, 25 minutes

Time left:
4 days, 8 hours, 25 minutes

Time left:
32 days, 8 hours, 25 minutes

Time left:
35 days, 8 hours, 25 minutes

Time left:
36 days, 8 hours, 25 minutes

Time left:
9 days, 18 hours, 25 minutes
Time left:
5 days, 2 hours, 25 minutes
Time left:
11 days, 2 hours, 25 minutes
Time left:
12 days, 2 hours, 25 minutes
Time left:
17 days, 2 hours, 25 minutes
Time left:
19 days, 2 hours, 25 minutes
Time left:
23 days, 2 hours, 25 minutes

Time left:
2 days, 15 hours, 40 minutes

Time left:
7 days, 8 hours, 26 minutes

Time left:
9 days, 7 hours, 26 minutes

Time left:
14 days, 14 hours, 36 minutes



















