

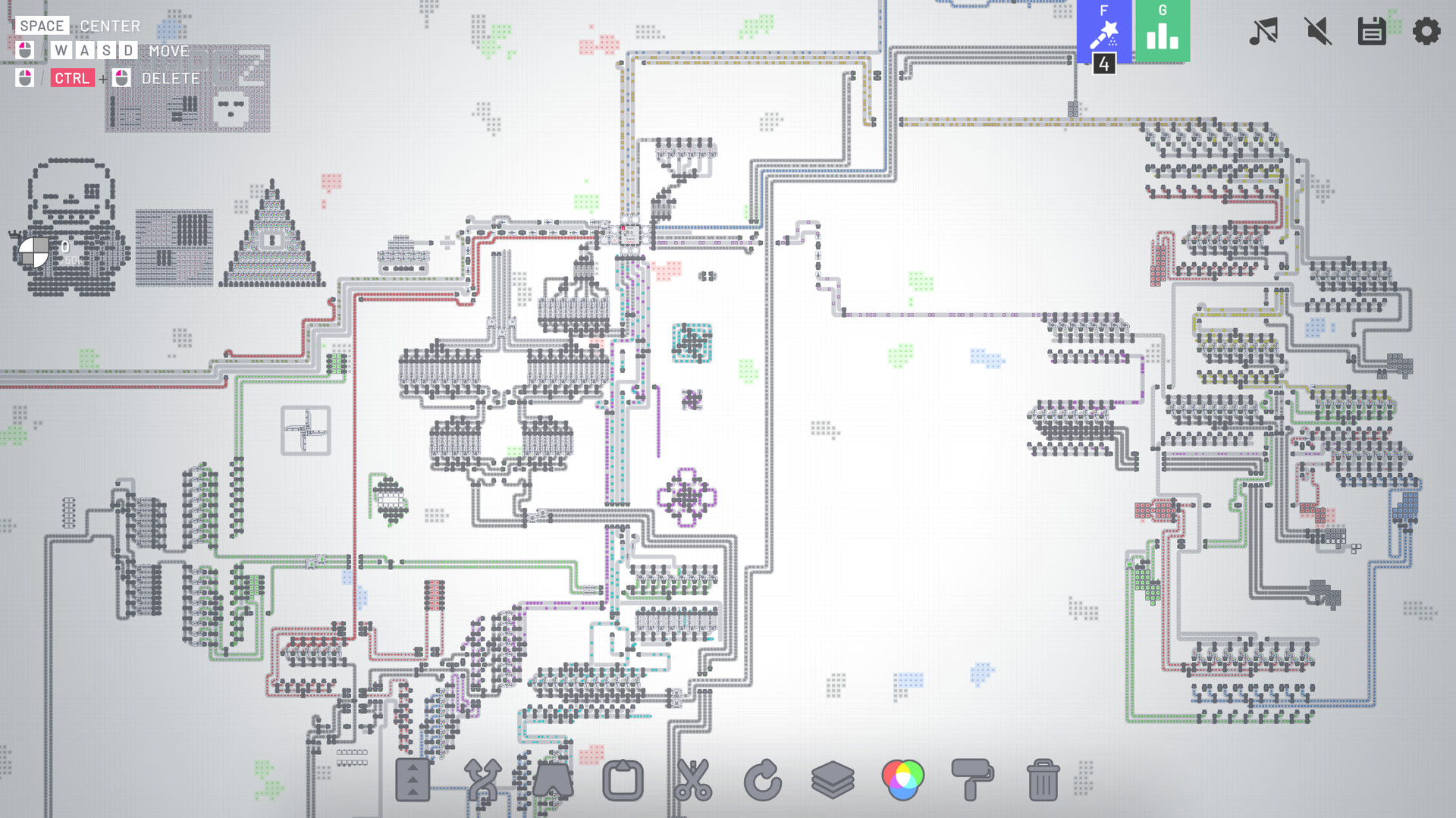
shapez.io is a game about building factories to automate the creation and combination of shapes. Deliver the requested, increasingly complex shapes to progress within the game and unlock upgrades to speed up your factory.
Since the demand raises you will have to scale up your factory to fit the needs - Don't forget about resources though, you will have to expand in the infinite map!
Since shapes can get boring soon you need to mix colors and paint your shapes with it - Combine red, green and blue color resources to produce different colors and paint shapes with it to satisfy the demand.
This game features 18 levels (Which should keep you busy for hours already!) but I'm constantly adding new content - There is a lot planned!
Standalone Advantages
- Waypoints
- Unlimited Savegames
- Dark Mode
- More settings
- Allow me to further develop shapez.io ❤️
- More features in the future!
This game is open source - Anybody can contribute! Besides of that, I listen a lot to the community! I try to read all suggestions and take as much feedback into account as possible.
- Story mode where buildings cost shapes
- More levels & buildings (standalone exclusive)
- Different maps, and maybe map obstacles
- Configurable map creation (Edit number and size of patches, seed, and more)
- More types of shapes
- More performance improvements (Although the game already runs pretty good!)
- Color blind mode
- And much more!
Hey everyone!
We get a lot of questions about performance, so we thought it would be a good idea to take you through our progress of optimizing Shapez 2 to run as smoothly as possible. We asked Lorenzo, one of our developers, to take you through everything. This is a very technical blog, so if you're not experienced with this stuff, feel free to skip this one.
Before you dive in, be sure to wishlist Shapez 2 if you haven't already! It helps us out massively. Thanks!
https://store.steampowered.com/app/2162800/shapez_2/
[hr][/hr]
Lorenzo here!
In our journey to evolve the shape of Shapez from a 2D game to a stunning 3D experience, we've encountered numerous exciting challenges and opportunities. This transformation not only adds depth to the game but also infuses it with more personality, gameplay possibilities, and aesthetic appeal.
However, this transition has not been without its fair share of obstacles. The move to 3D has introduced a multitude of development challenges, spanning game design, artistic direction, and technical implementation. Perhaps one of the most significant technical challenges lies in rendering 3D objects.
In Shapez 1, rendering was relatively straightforward, with one sprite per building. In the 3D realm, each building has thousands of triangles to render, different materials and animations. For large factories, this requires a considerable amount of optimization, both in the simulation of these entities and in the rendering process.
In this devlog we go in-depth in a lot of the rendering optimizations tailored specifically for Shapez 2, as well as what is missing and what are the next steps in keeping a stable frame rate with massive factories.

Introduction
Performance has always been at the forefront of our development philosophy. Right from the beginning, we made deliberate choices to ensure the game's efficiency. In the game context, we can split the performance into three categories: Simulation, Rendering & Interfacing. The simulation changes from Shapez 1, as well, as some insights of how we are pushing the performance for large factories can be found in Devlog 001. The interface, meaning, every interaction that the user communicates with the game and reflects both in the simulation and rendering, is very circumstantial. It can be optimized on a case-by-case basis. The rendering issue, however, is one of the biggest challenges to overcome. We already did a lot, but given the massive scope that we aim for, it might not be quite enough yet.
To kick this devlog off, let's first discuss a bit about how the rendering works (in a very high-level way).
Overview of the rendering workflow (CPU-GPU)
It is important to understand that CPUs and GPUs serve very different purposes. I like to think of the CPU as the solver of all problems: no matter what you throw at it, it can handle it to some degree. Sure, if you jump around instructions and memory, the performance will degrade, but it is not compared to how a GPU would handle it. CPUs pipelines help process many instructions per cycle while branch predictors try to minimize the amount of incorrect jumps and L1, L2 & L3 caches reduce RAM fetching latency. On top of that, processors today come with many cores, but leave the responsibility of using such cores to the developer. More on this later.The GPU on the other hand is a hardware specialized in processing a single instruction for a very large amount of data. That's why it shines in computer graphics and game development: just think about the number of pixels in your screen, the number of polygons a model has or the amount of rays that need to be traced to render one frame of a path-traced scene. As mentioned in the previous paragraph, it is not so good at switching state (branching). In other words, drawing two different objects once is slower than drawing one object twice.
With that in mind, the processor is the part that will handle all the input, interfacing, and simulation for game development. And after all that, it will dispatch to the GPU what it wants to draw. In order to draw something into the screen, the CPU needs to pass some data to the GPU: a mesh, transformation matrix and a shader (yes, this is very, very oversimplified). Imagine if we want to draw our very hard-working belt. The CPU, after processing the simulation, asks the GPU: Hey, would you be so nice to draw this belt mesh at this position using this shader right here? While youre at it, draw this shape in this position slightly above the belt and so on.
Culling
The CPU tells the GPU (nicely or not) what it should draw, and the GPU complies without hesitation. What data is communicated is crucial for performance. Imagine telling the GPU to draw every object in your scene? Even the ones behind the camera? The GPU does not have a lot of context to work with and will process most parts of its rendering pipeline until realizing that the object is not in view. Defining which objects are visible in the current view is called Frustum Culling. Ideally, this should be performed by the CPU.The way that the data is communicated is also very important, that's why the Khronos Group at some point realized that their OpenGL was too high-level and created Vulkan, a very low-level API for interoperating between CPU/GPU. Unfortunately, Steam character limit wont allow us to go in depth, but you can read more about it here .
What we have been doing
Alright, now that we are in sync regarding how CPU and GPU need to communicate, let's talk about what already has been implemented in Shapez 2 to maximize the performance.
Game Object avoidance
We steered clear of Unity's Mono Behaviors for core components that demand high performance. Except for the UI, almost all of our systems are written without Unity components. This allows us to employ a better architecture following C# principles and have fine control over all aspects of the game, including the performance.GPU instancing
In Unity, to draw geometry on the screen, draw calls are issued to the graphics API. A draw call tells the graphics API what to draw and how to draw it. Each draw call contains all the information the graphics API needs to draw on the screen, such as information about textures, shaders, and buffers. Less draw calls are better, as the GPU has less work to do and less switching to perform. One of the most important optimizations in the rendering of Shapez 2 is using the full potential of GPU instancing: grouping objects with the same mesh and shader in a single draw call.
In my assignment to enter tobspr, I was tasked to create a shader that would logically render many materials based on some mesh data. So I did, but In order to fully explore the potential of such a shader, I decided to run some tests comparing the performance of drawing Game Objects vs. batching all rendering in a single instanced draw call. For the test, I used 64643 = 12k low-poly belts and the results were astonishing:

Material combination
Our buildings and space stations are composed by different materials:
Since each building might be composed using multiple materials, this would require multiple draw calls per building. To improve it, we combined all of them in a single shader. This allows us to have only one mesh for each building main part which is drawn with a single material, thus a single draw call. The material split is made inside the shader using the information of the UV0 channel, which encodes the material index per vertex data. Additional moving parts and effects need to be drawn separately.

Mesh combining
Having a shared material for all buildings reduces tremendously the number of draw calls, but it also provides the foundation for a very interesting optimization: mesh combination (also sometimes called mesh baking). At runtime, buildings on the same island are combined into a single batch dynamically. Since the material is unified and the mesh contains all buildings, we can render tons of buildings with the most varied materials in a single draw call.The example below uses only two combined meshes to draw all of these buildings main components:


Level of Detail (LOD)
We take vertex count very seriously, even one extra vertex can become 300,000 extra ones when rendering very large factories. To support very detailed, yet scalable meshes, we created different meshes for each building in different levels of details. The model that is actually presented on the screen is calculated at runtime based on the camera distance.
What's the problem, then?
With all those optimizations, the rendering performance should be excellent, right? Well, it is, but we always want more. Better performance means bigger factories, more compatibility with older hardware and less hardware pressure. The question naturally becomes: what can be optimized next? So far, you might have recognized a pattern in the optimizations above: they are all targeted at optimizing the GPU rendering process. Less draw calls, less vertices, less context switching. Indeed, the hardest part of rendering is always focused on the GPU, and were getting very close to the scale we are aiming for. However, all of these techniques put further pressure on the CPU, which already needs to deal with the simulation part. As Tobias always says, each 0.1ms saved from the rendering will be well spent in the simulation, allowing for further complicated factories to run.
During development, we avoided using Unity components as they are generally not very performant. Core components have been written with performance in mind, employing several algorithmic optimizations to ensure everything runs smoothly. However, the code executed by the CPU is still written in C#. This comes with limitations on how performant it can be, as the language offers a trade-off between productivity and runtime performance.
The table below provides some insights about the performance of each language for single thread tests. The algorithm executed is the same, yet the time difference to execute it can be abysmal.

Source
Enter DOTS (or part of it)
Unity is a beginner-friendly engine with a lot of features both to help you get started and for veterans to write very complicated systems. However, although there are many highly optimized systems and a high influx of new optimizations, the underlying structure was not created with performance in mind. During the past decade, the engine race was quite fierce between Unreal and Unity. Numerous debates over which one is the best one, forced Unity hand to take their lack of performance into consideration, thus yielding a completely new paradigm with a powerful tool belt to back it up: the Data Oriented Technology Stack (DOTS).
It was created with the slogan: Performance by default and since its impressive debut in Megacity (2019), has received dozens of improvements. DOTS is a combination of technologies and packages that delivers a data-oriented design approach to building games in Unity. Applying data-oriented design to a games architecture empowers game creators to scale processing in a highly performant manner. It is composed mainly by three technologies: ECS for Unity, Burst Compiler & C# Job System.
ECS is a data-oriented framework focused on structuring the code in a very different manner than traditional Object-Oriented (OO). Instead of mixing and matching data and implementation. As the name suggests, ECS has three main parts. Heres an excerpt from Unitys own documentation:
- Entities the entities, or things, that populate your game or program
- Components the data associated with your entities
- Systems the logic that transforms the component data from its current state to its next state
DOTS looks amazing on paper: a completely new approach to design your game with a clear division between data and logic that is also very efficient due to the contiguous nature of ECS and the underlying tools that back it up. In practice, however, using ECS on production was not advised until recently, since the package was still in development. It also comes with a heavy price to pay if your code is already written and although it is easier to maintain, the initial code creation can be much more challenging. For the last few years, the API changed dozens of times, many of these rendered previous implementations obsolete. A lot of core systems, such as physics, audio and multiplayer have also stayed in pre-release for the last couple of years. Using ECS for production was risky and not advised.
The good news is that the Burst Compiler and the Job System work independently of ECS, and we get to enjoy their performance benefits without the hassle of rewriting all of our codebase from scratch.
Burst Compiler
Burst operates within constraints and patterns that empower the compiler to perform much of the heavy-lifting. These are:- Limited C# Subset: Burst Compiler operates on a constrained subset of C# and does not support, by design, inefficient patterns.
- No Garbage Collection: Manual memory management eliminates the need for garbage collection, reducing time spikes.
- No References, Just Plain Data: Data is stored without references, facilitating faster memory access.
- Adjacent Memory: Most jobs are written reading/writing to contiguous memory, making it possible to use vectorization (SIMD) and efficient use of CPU caches.
- Parallelism with Job System: Enhanced parallel processing capabilities.

Source
Job System
In the game development realm, many games process everything in a single thread, not using the full potential of the processor. Heres why:- It can be challenging to split the workload between multiple threads;
- Most games are not coded with that in mind and have data dependencies everywhere;
- Race conditions, deadlocks and complicated issues might arise
- Most games do not have a lot of processing to do (generally the rendering is the performance culprit)
Restrictions
The Burst Compiler and the Job System almost seem magical given the increase in performance they can provide. They come, however, with a hefty price to pay: it is way harder for your code to comply with them. A lot of constraints restrict how you should structure your code. In short, they do not support managed references. You need to stick with bare bones data-only structures and some pointers to help structure collections. And that's all you got. The benefit is that you can write very efficient code. If you are curious about what is allowed and what is not, here is an overview of what is supported by Burst:[table noborder=1 equalcells=1]
*ECS actually supports when defining systems that will execute on archetypes, but it is just syntax sugar, the lambda is converted down to a simple function
As shown, the Burst Compiler only accepts a very small subset of C# that feature-wise looks a lot like C. Furthermore, both Job System and the Burst Compiler do not accept references to managed code. To understand managed vs. unmanaged, it is crucial to first understand how the memory allocation works.
C# memory management
In the C# context, whenever you create a new instance of a class (and in many other circumstances), it allocates the class data in the heap to avoid loss. Once again, C# makes it easy for programmers because it implements a garbage collector.On the other hand, if you use C# structs, the data is passed around on the stack by default. That means that using a struct, per se, does not allocate memory on the heap. When the function reaches its end, the data is automatically gone. The inconvenient part is that the programmer must guarantee that the data is properly copied between functions since it does not survive scope ending.
Managed vs. Unmanaged
With this in mind, we further refer to data allocated and disposed by C# simply as managed. This includes all instances where data is allocated in the heap. But what is unmanaged data, then? Well, it is not that this memory is not managed, it is just that it is not managed by the compiler. Instead of having the compiler solve it for us, the programmer becomes responsible for allocating and disposing it. Forgetting to dispose unmanaged memory will cause memory leakage. Premature disposal of it might invalid memory accesses and crashes. In Unity, this is done using a handful of DOTS extensions that are very similar to C's malloc and free functions.It is important to note that unmanaged memory should not reference a managed one, as this can create a lot of issues with the garbage collection and in general with the C# memory management. In the Burst context, accessing managed references is not even allowed, forcing the programmer to rely on blittable structs and unmanaged memory.
Garbage collection
The garbage collector is a system component responsible for managing memory by reclaiming and deallocating memory that is no longer in use. It identifies and frees up memory occupied by objects or data structures that are no longer referenced by the program. This process helps prevent memory leaks and simplifies memory management for developers, as they don't need to manually release memory.Garbage collection can introduce performance overhead compared to scenarios with manual memory management. It adds periodic pauses to a program's execution to identify and reclaim memory, which can result in unpredictable delays. These pauses can be especially problematic for real-time or performance-critical applications, causing jitter and latency issues.
How to render with DOTS?
The limitations on the Burst Compiler and Job System also requires no access to managed API, including most of the Unity systems. Game Objects? Nah. Physics? Think again. Graphics API? Big no. This created a big problem for us. We wanted to use DOTS to speed up the culling process, but without access to the graphics API, there was no way to actually submit the render commands to the GPU. One option was halting the main thread and waiting for the jobs to complete at the end of the frame. That did not yield any performance gains, though, as the overhead was too big for dispatching the jobs, waiting for their completion and submitting the computed data from managed code.
To properly solve it, we had to research how Megacity solved it back in the day. Luckily for us, not only is the API available, but also received a recent update in Unity 2022.2 that improved the usability. The Batch Renderer Group API was designed to be accessed by unmanaged/native code (DOTS compliant). The way it works is that at the end of each frame, the BRG generates draw commands that contain everything Unity needs to efficiently create optimized, instanced draw calls. As the developer, we can fill in that draw call information and specify exactly what we want to draw from within an unmanaged context. Meshes and materials are managed types that need to be worked around. In BRG, we register them during a managed context and assign a unique ID to them. This ID is just a type-safe structure holding an integer, allowing us to reference meshes and materials from within the unmanaged code.
Space Background Decorations
Now, as mentioned, writing code supported by the Job System and the Burst Compiler is harder than writing regular C# code. Both technologies can be considered recent and, although quite mature, we still approached the problem with caution. Instead of refactoring dozens of rendering classes and completely switching to Burst-compiled jobs, we opted for focusing our attention on a very isolated system: the background rendering. The background has no relation with the simulation and, except for the camera data, has no dependency with any other class. That provided us the perfect experimenting backyard where we could test the power of DOTS without the massive amount of work required to implement it everywhere. Bonus: the background rendering was using quite a lot of the CPU, and optimizing it yielded good results in many setups being bottlenecked by the processor.More specifically, we focused on the background rendering of the chunked decorations, because they are dynamically generated based on where the player is looking. There is a lot of optimization that could be made algorithmically to improve the decorations, but we kept them the same to analyze how impactful using DOTS could be. The decorations are generated based on noise the first time they are discovered and cached for future queries.
The Batch Renderer Group has several interesting features that might fit a lot of games well:
- Persistent GPU
- Scriptable layout
- DOTS instancing shader variant
- Compatible with DOTS
To understand how the improvement works, heres a breakdown for a simple scene without many buildings using the previous solution. By inspecting the Profiler data closely, it is possible to check that the main CPU loop (the left side) takes most of its time culling the decorations (Draw Managed Background Particles / Asteroids / Stars). Only after they all finish, the data submitted to the GPU can start being processed.

The main change we implemented is running the decorations culling using burst compiled jobs. These jobs are scheduled as soon as we have the camera data information (the only data the decorations need to be culled). While the main thread is busy processing the inputs, simulation and other rendering, the jobs execute concurrently as can be seen in the image below:

The jobs are much faster than their original managed counterpart, but even if they werent, we would see improvements due to the parallelism. When the main thread is done with the other tasks, the decorations are already culled and everything is ready to be dispatched to the GPU. In these example frames, the CPU time reduced from 9.21ms to 2.35ms, halving the total frame time.
There are many optimizations missing for the jobs that would make them run even faster:
- Due to the nature of a culling algorithm, vectorizing the code is very challenging, but we believe a part of it could still benefit from the AVX set;
- You can see that each decoration is culled sequentially in a single thread. Each decoration could dispatch one job per thread, or the jobs could be scheduled to run at the same time. For higher numbers of cores, both could be combined to achieve even more parallelism.
Mesh combiner
Besides the background, one of our highest bottlenecks comes from combining meshes. As mentioned earlier, combining meshes at runtime reduces a lot of pressure on the GPU, which can draw many buildings with many materials in a single draw call. The mesh combination process, however, needs to be processed by the CPU. In order to reduce the pressure on the processor, a new mesh combination system was written using the Job System and Burst Compiler. The goal was creating a system that could handle combination requests from both managed and unmanaged code, while the combination itself would be performed in a job to reduce the amount of work the main thread has to do.In-game results
The FPS improvements we have seen in most systems are very exciting, but the individual performance improvements are even more. Before we dive into the numbers, let me quickly explain the difference between the cached and uncached tests: since the decorations are created dynamically based on the seen chunks and the map is infinite, there is no way to bake all the decorations beforehand. Whenever a chunk is seen for the first time, the decoration for that chunk is generated from noise and cached for further lookups. One issue in the previous version was that turning the camera fast and discovering many new chunks at the same time would cause a huge spike in the frame time. It would also generate a lot of memory garbage to be collected. This is not a problem anymore with the new solution, as it can handle the generation much faster.Disclaimer: these tests are not averaged. They are a representative average frame manually sampled from the profiling pool. Tests are using an i3-9100F & RTX 3060 Ti.



For the average case, the performance is increased by 6x. However, since it is running in parallel, the effective benefit we see is 28x faster culling. This only holds true if the jobs finish before the main thread, which requires the main thread to be busy and the other threads not so much. Further improvements will need to consider balancing what is processed where. The more tasks we move to other threads, the less impactful these changes are.



Now, looking at the uncached case, which is the one that requires more from the CPU, we can see that for generating new chunks both scenarios struggle more than with cached data. While the original one drops the FPS substantially, the Burst version still delivers runtime acceptable performance. Most of the jobs time was used in the lazy mesh combination. The combination still requires some improvements on the managed side (some balancing), but some delay is expected (something close to 0.5ms per frame that fetches mesh data). If we schedule one per frame, its not an issue, but the meshes might take too long to bake. That's why we need some smart balancing.

These results should give you a rough idea: 30x 120x improvements in the main thread. 6x 114x overall. Now, lets also check the memory improvements and the actual FPS improvements in-game.


From the benchmark, you can see that the average FPS improved. The 1% however, was the most affected metric, highlighting that the new version should handle processing spikes much better.
Now what?
Eventually we will reach the limit of what we can do to optimize the factories, but we are still not there yet. The next steps are more challenging, but we have some optimizations prepared. The first step is moving all the mesh combinations from managed to unmanaged code. This is easier said than done. To fully support it, there is an incoming headache of standardizing the vertex layout formatting or solve it generically, balancing problems to figure out and more optimizations to research regarding using the main thread for computing.
Besides it, we have many checks and benchmarks aligned to make sure everything is compliant with the performance standards we established. After this is done, ideally, we would like to move the whole rendering to burst compiled jobs, but that is a complicated task that involves lots of refactorings, structural changes and many Unity crashes to go.
You can see it for yourself! Starting from Alpha 8, we also created a new benchmarks' menu, which can be used to evaluate the performance running the exact same scenario with multiple configurations.

Please let us know if you also benefited from the changes. Hurry up, they will probably get removed in Alpha 11
[hr][/hr]
So, that's about everything! We hope you enjoyed this deep dive, and we'll see you again in two weeks.
~Tobias, Lorenzo & the shapez 2 team
Join the community:
Twitter / X YouTube TikTok Discord Reddit Patreon
[ 6376 ]
[ 5865 ]
[ 751 ]
[ 2194 ]

Time left:
356103 days, 11 hours, 59 minutes

Time left:
356103 days, 11 hours, 59 minutes

Time left:
7 days, 19 hours, 59 minutes

Time left:
35 days, 19 hours, 59 minutes

Time left:
38 days, 19 hours, 59 minutes

Time left:
39 days, 19 hours, 59 minutes

Time left:
13 days, 5 hours, 59 minutes
Time left:
0 days, 13 hours, 59 minutes
Time left:
1 days, 13 hours, 59 minutes
Time left:
8 days, 13 hours, 59 minutes
Time left:
14 days, 13 hours, 59 minutes
Time left:
15 days, 13 hours, 59 minutes
Time left:
20 days, 13 hours, 59 minutes
Time left:
26 days, 13 hours, 59 minutes

Time left:
2 days, 23 hours, 59 minutes

Time left:
10 days, 20 hours, 0 minutes

Time left:
12 days, 19 hours, 0 minutes

Time left:
18 days, 2 hours, 10 minutes



















